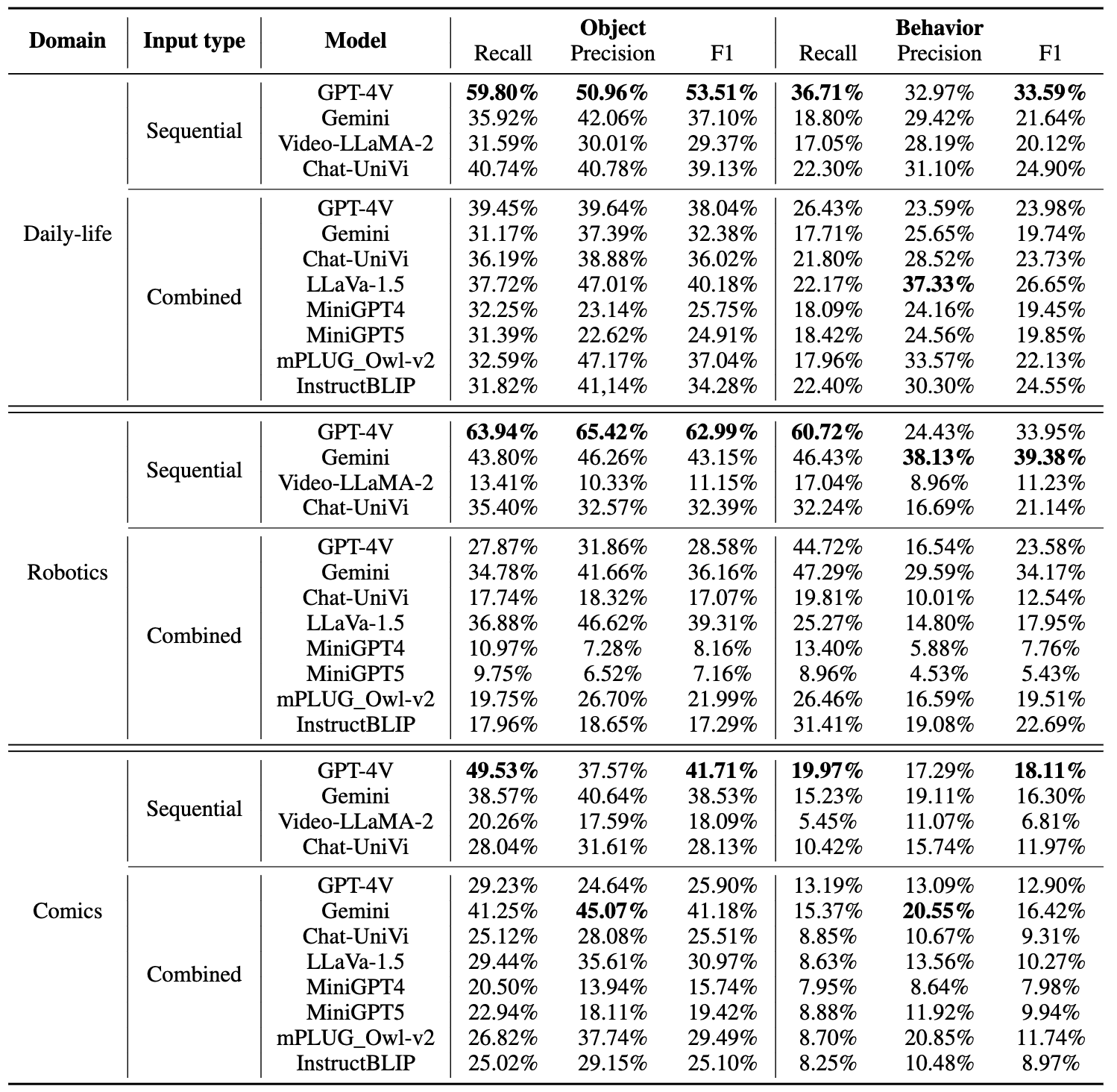
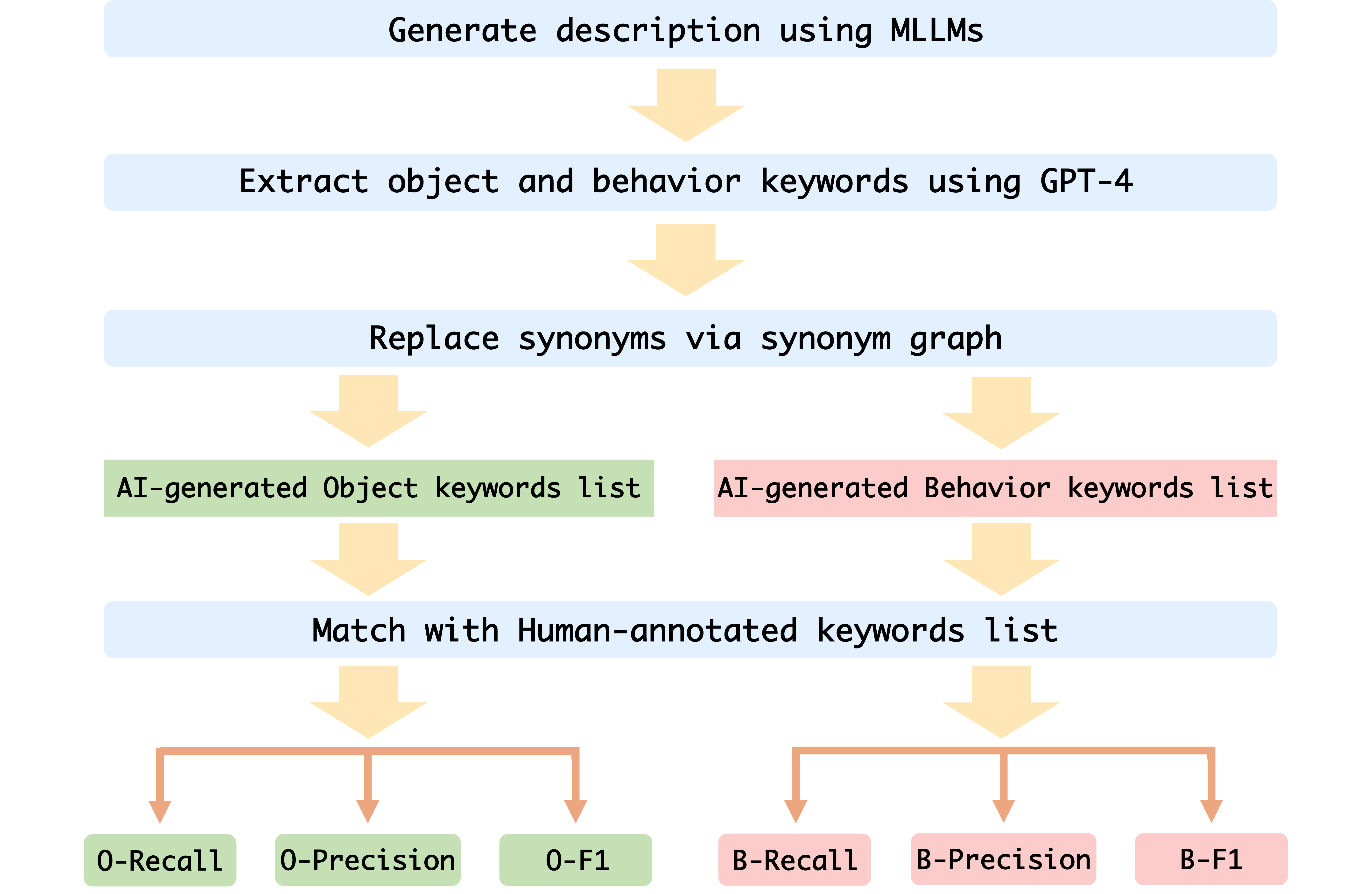
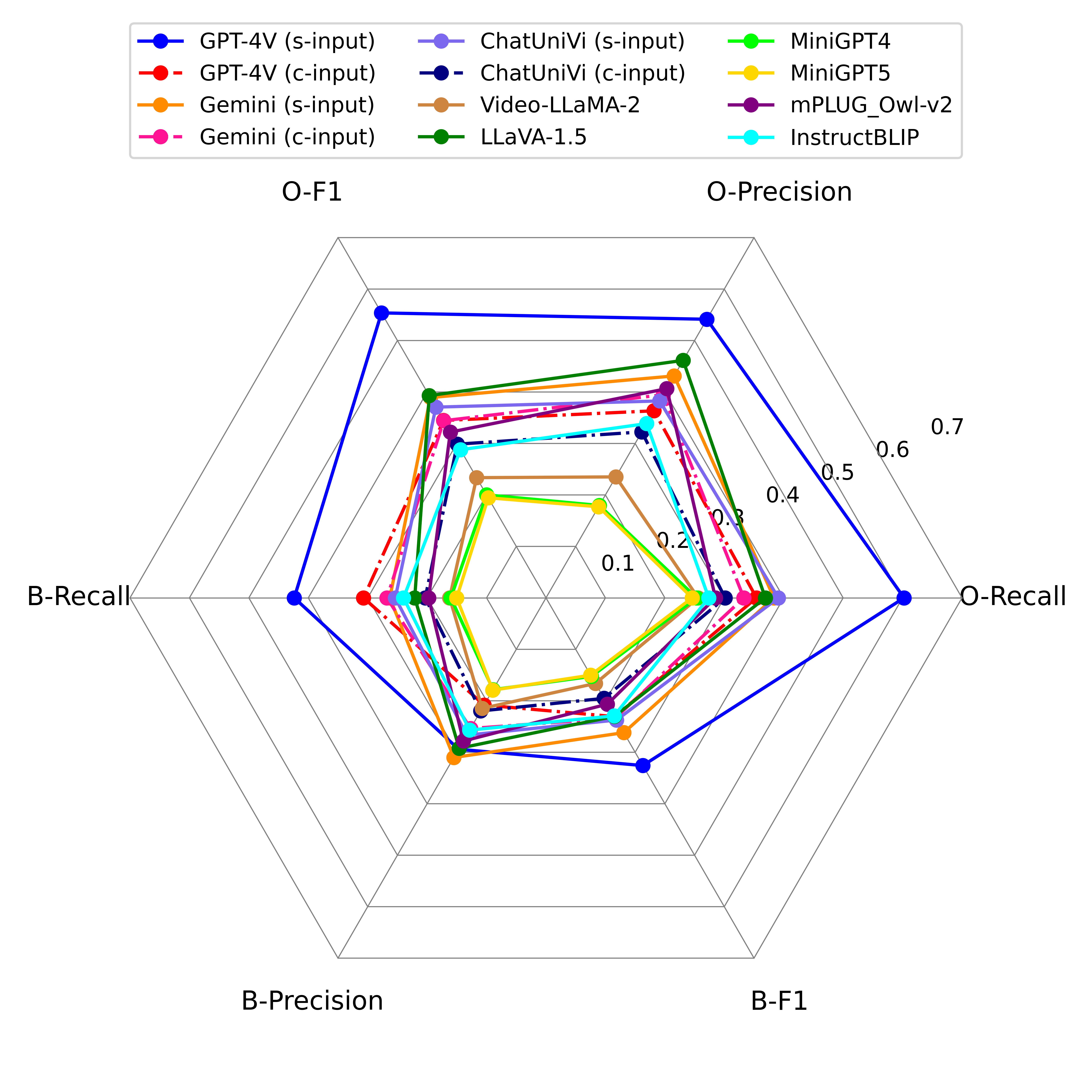
Recall. Precision, and F1 scores of Object and Behavior on Val set of  Mementos.
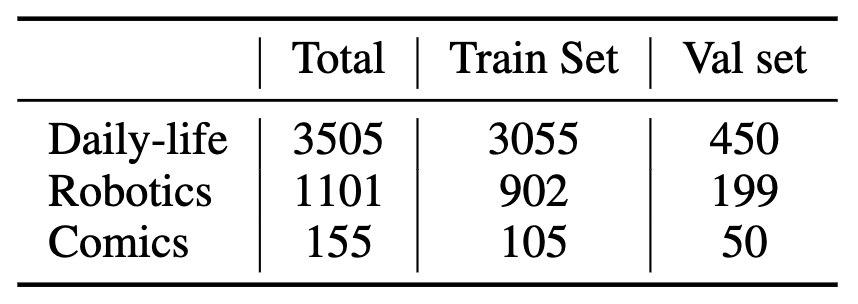
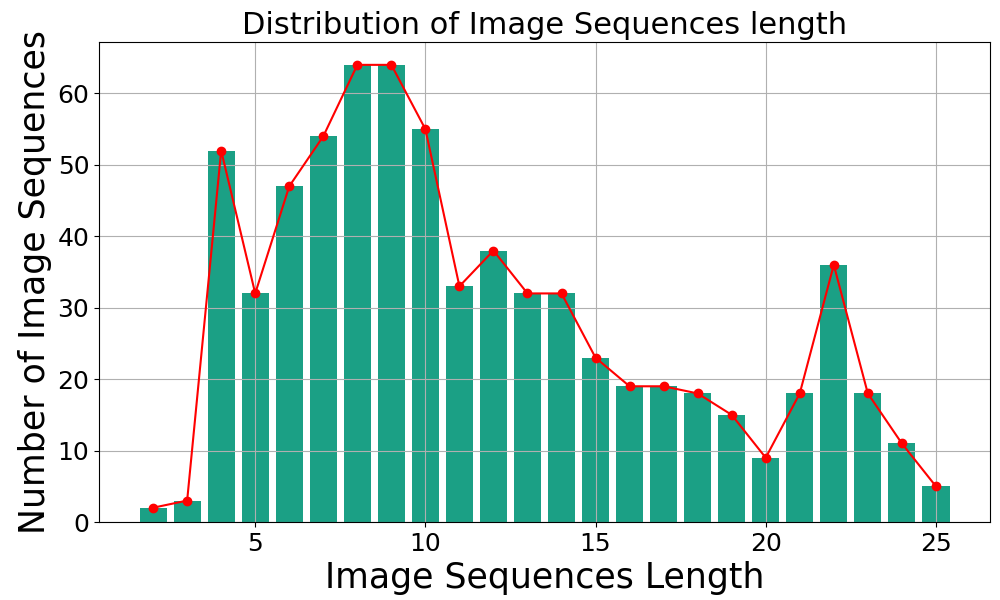
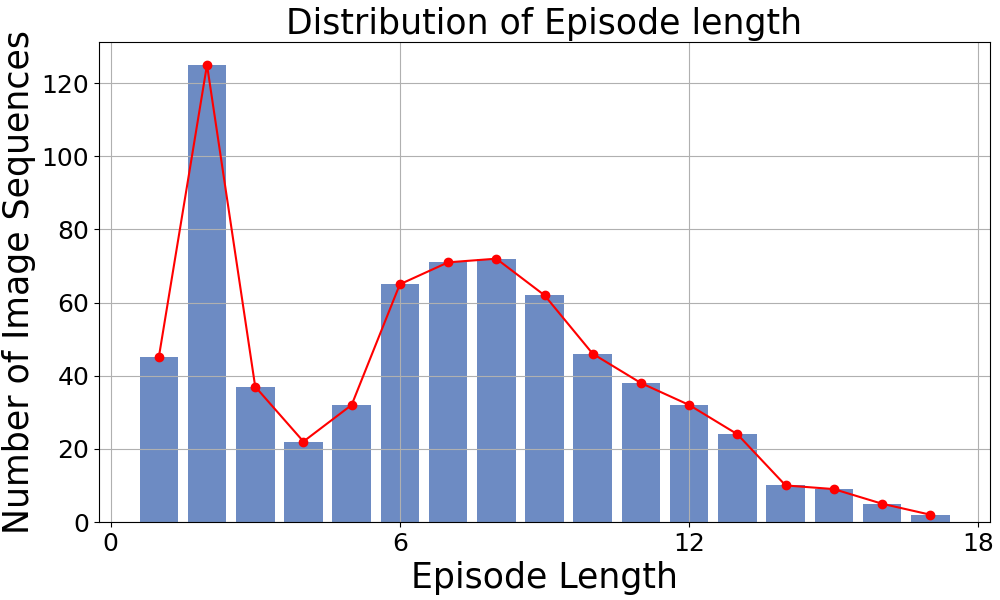
Mementos.
| # | Model | Input type | Source | Date | Avg | Object-Recall | Object-Precision | Object-F1 | Behavior-Recall | Behavior-Precision | Behavior-F1 |
| 1 | GPT-4V 🥇 | Sequential | Link | 2024-01-20 | 45.68 | 60.24 | 54.13 | 55.36 | 42.36 | 29.40 | 32.58 |
| 2 | Gemini 🥈 | Sequential | Link | 2024-01-20 | 33.98 | 38.36 | 43.12 | 38.91 | 26.28 | 31.01 | 26.18 |
| 3 | LLaVA-1.5 🥉 | Combined | Link | 2024-01-20 | 32.78 | 36.90 | 46.14 | 39.29 | 22.09 | 29.22 | 23.01 |
| 4 | Chat-UniVi | Sequential | Link | 2024-01-20 | 31.69 | 39.09 | 38.26 | 37.06 | 25.36 | 26.67 | 23.74 |
| 5 | Gemini | Combined | Link | 2024-01-20 | 30.44 | 33.28 | 39.47 | 34.42 | 26.76 | 25.38 | 23.33 |
| 6 | GPT-4v | Combined | Link | 2024-01-20 | 30.13 | 35.41 | 36.34 | 34.46 | 30.70 | 20.82 | 23.07 |
| 7 | mPLUG_Owl-v2 | Combined | Link | 2024-01-20 | 28.26 | 28.51 | 40.65 | 32.20 | 19.74 | 27.81 | 20.64 |
| 8 | InstructBLIP | Combined | Link | 2024-01-20 | 27.10 | 27.37 | 33.86 | 28.77 | 23.98 | 25.69 | 22.92 |
| 9 | Chat-UniVi | Combined | Link | 2024-01-20 | 25.67 | 30.14 | 32.24 | 29.86 | 20.32 | 21.97 | 19.52 |
| 10 | Video-LLaMA-2 | Sequential | Link | 2024-01-20 | 21.13 | 25.59 | 23.50 | 23.35 | 16.21 | 21.47 | 16.62 |
| 11 | MiniGPT4 | Combined | Link | 2024-01-20 | 18.73 | 25.33 | 17.95 | 20.01 | 16.02 | 17.82 | 15.26 |
| 12 | MiniGPT5 | Combined | Link | 2024-01-20 | 18.28 | 24.58 | 17.69 | 19.44 | 15.04 | 17.93 | 15.02 |
💡 Sequential means frames from the image sequence are input sequentially for reasoning.
💡 Combined means combining all frames from an image sequence into one composite image as MLLM input.
🚨 To submit your results to the leaderboard, please send to this email with your result json files.
🚨 For more submission details, please refer to Evaluation.